
Slopbashing
Building better generative 3D design tools


Designing bark sculptures from Rhino screenshots
I was one of the first thousand or so people to use Midjourney, and this was the first time I felt addicted to a generative AI tool. It produced strange images fast enough to keep you in creative flow **and upheld the illusion that it was capable of generating anything, if only we gave it the right prompt. I spent dozens of hours generating thousands of images, and would trawl though the creations of other people on the discord server to learn tricks or steal ideas for keywords that pushed the model into some fascinating aesthetic space. But newer versions of Midjourney gradually smoothed out these desirable flaws. Users on discord all seemed to be interested in creating the same kinds of images, and the sheer quantity of sameness made it much harder to find a muse. And suddenly, the sugar rush was over. The slop had arrived.
There are three trends at the moment that I think are producing a lot of new slop. One is Ghiblifying images in ChatGPT. Another is vibe-coding flight simulators with increasingly superhuman coding models. The other is making 3D game assets from image prompts. Generally speaking, I think slop is bad because it is meaningless and wasteful. But I also think that these emerging capabilities of generative AI should be useful design tools. Editing images with text feels like more of an iterative design process than one-shotting images with prompts. And generating 3D models without the technical barriers of using CAD should facilitate different kinds of creative flow. So instead of slopbashing (hating on slop), maybe we could instead try kitbashing with rapidly generated, perhaps somewhat sloppy, content. Maybe we could even vibe code the tools we need.
Improving the Text to 3D flow in Rhino
Generate anything you want! So long as its a video game asset.
We have already explored integrating Runchat with Rhino in order to iteratively generate code or control parts of the grasshopper definition with language models. At the time we tried integrating text to 3D models in Runchat, passing the resulting links to GLB files back to grasshopper where we used Python to download them. Parsing the GLB content to create meshes and materials in Rhino was going to be too tedious, so instead we just downloaded the GLB to My Documents and asked the user to drop it into Rhino. No big deal right? Wrong. These kinds of tiny impositions on creative flow are always a big deal.
There are a few barriers to a decent text to 3D workflow in Grasshopper. These are:
Most 3d generators work with image inputs, and there isn’t a good way to generate images in grasshopper
There isn’t even a good way to view images from the internet in grasshopper (except with plugins, though this is still clunky)
3d generators return links to GLB models hosted on the internet somewhere, and as we already found there isn’t a good way to download or load them.
Grasshopper doesn’t have a good way of rendering materials with textures (except with plugins, though this is still clunky)
We hadn’t tried to build all of this into the Runchat Grasshopper plugin just because the complexity made it feel like it wouldn’t be a good investment of our time. But this changed a few days ago with the release of Gemini 2.5 Pro, a new model from Google that is supposedly quite good at code. Because Grasshopper plugin development is relatively niche, we have had limited success with other models (e.g. Claude Sonnet) at vibe-coding grasshopper plugins that require a fairly intimate understanding of the Rhino and Grasshopper SDK. Would Gemini 2.5 Pro be any different? This felt like an opportunity to quickly re-evaluate the cost-benefit of implementing these features in our Grasshopper plugin.
Creating Grasshopper Components with Gemini 2.5

An example of prompting Gemini to start creating a Grasshopper plugin
What is fascinating about Gemini 2.5 Pro is that it’s thinking is a) visible and b) self reflective. The model will often come up with a plan and then refine this plan during the thinking process as it identifies various gotchas to what it intends to implement. I presume that this kind of re-thinking is baked into the models system prompt and RL training process, where it generates a though and then critiques or reflects on that thought before continuing. As a result, Gemini 2.5 Pro seems very good at weighing up tradeoffs between implementing what the user has asked for exactly, and interpreting their intent to implement a better solution. I found reading through the thinking tokens far, far more useful than reading the summary output by the model along with the code. Reading the thinking tokens helped me understand the problem and recognize things I might not have considered. Like Midjourney, this is the first time I have been able to suspend disbelief and pretend that this model can actually write code for just about anything. It can’t, it still hallucinates, but several times the thinking log helped me identify where the model’s reasoning was slipping up and leading it down the garden path.
The very large context window for Gemini also means that these hallucinations can sometimes be addressed by simply pasting the entirety of a github repository into the prompt. In the case of the GLB viewer component, this meant providing most of the code for the SharpGLTF library so that Gemini could correctly convert from the SharpGLTF schema to the Rhino DisplayMaterial class. The SharpGLTF documentation is fairly limited and there are few examples of implementations on Stack Overflow and the usual places, so it would have required picking over this source code to implement this conversion ourselves.
Gemini 2.5 Pro does have a tendency to re-write large chunks of code or subtly change a single line even when you direct it not to as it is very opinionated about best practices and efficiencies. This meant that the usual truism of vibe coding being easy to start and hard to refine is still the case with this model. However, because you can provide the model with so much context (the entirety of the existing plugin, the entirety of the libraries we are using) it was surprisingly close to one-shotting the GLB reader. Reading the thinking tokens demonstrated a fairly deep understanding of the nuances of the Rhino and Grasshopper SDKs and the approach Gemini used to render materials with textures in Grasshopper without having to rely on the Rhino material table was effective. In the end Gemini 2.5 Pro managed to implement:
Async downloading and parsing GLB files
Reading all GLTF nodes and parsing to geometry and textures
Rendering in the viewport
Creating and disposing of temporary image files
Baking geometry and textures to Rhino

GLB files with textures in Grasshopper
Because this worked so effectively we then tried building an image viewer component. This proved to be more challenging because we wanted to override the default GH_Component Render() method and draw a bitmap to the canvas instead. I suspect that with a well defined brief for this component we could end up with a good UX, but it didn’t feel one-shotable without that and we settled for simply resizing and drawing over the top of the default component. This is sloppy I know, but it works.

A very simple component for viewing multiple images from the internet in Grasshopper
Image and Mesh Generation in Runchat
Something I am interested in facilitating is a tool that lets us:
Quickly generate images using any image model we like, without leaving grasshopper
Previewing these images in Grasshopper
Quickly generating mesh models with textures from these images, using any mesh generating model we like, without leaving grasshopper
Preview these meshes in Grasshopper
Now that we have built the two preview components, all that is left is to create the two Runchats - one for image generation and one for mesh generation. The image generation one is stupidly simple:

A runchat for generating images from prompts that you can run via API
Here it is, featuring our new settings bar. The idea here is that we set the image model we want to use in Runchat, then we only need to provide a prompt in grasshopper. If you add a Fal api key to runchat then you can add any of their models to the image node, meaning that we can now easily use just about any image generation model in Grasshopper without having to change our grasshopper definition or plugin at all. The second a new fancy model comes out, add it in Runchat and pick it in the image node. That’s it.

And here’s the mesh generating Runchat. This one has a couple more nodes in it because we want to be able to support switching between different mesh generation models using a dropdown, and we need to grab the url to the GLB from the API response. Like with the image node, if a new model comes out that we want to use in Grasshopper we can just add it to our Runchat - no change to Grasshopper or our plugin required. So now that we have these two Runchats set up we can use them both in grashopper:

The first Runchat component makes a request to our Image runchat, generating an image from the prompt set in our panel. Then we take the image URL and pass it to the second runchat component which makes the request to the mesh generation API. This spits out a url to the GLB once it’s finished, that we can then use the LoadGLB component to display. Voila.
Use Cases: Kitbashing
The clearest benefit to having a seamless text to 3D workflow in Rhino is the ability to immediately manipulate the meshes that are generated. This means baking, copying, transforming and assembling them together to make more complex assemblies. This process is a bit like kitbashing - rearranging collections of models in new creative ways. Using the generated objects as parts instead of finished products feels less sloppy. It also means that the biases of the model aren’t as present: the models have a tendency to produce symmetrical objects and characters, for instance, but these can be smooshed together to produce asymmetry and strange bodies.
Use Cases: Mesh Retexturing
Something I have been doing a lot in design studios is exploring using diffusion models for mesh texturing. This has always been a pretty clunky workflow from Rhino:
Create a 512x512 viewport
Save the view
Capture a screenshot
Upload the screenshot to some control net model and generate an image
Texture map the mesh using the camera projection
Reproject the image onto the mesh
It would be nice to be able to streamline this whole process from grasshopper. To do this, we added two more simple utility components to the plugin. One for uploading screenshots to Runchat, and one for assigning UV coordinates and image textures based on the current camera projection. Now we can create a runchat that takes a depth map from Rhino and generates an image with a control net model from Fal, returns the resulting image, and projects it onto our mesh. All within grasshopper! This is pretty fun as a design tool.

You can try this Grasshopper definition out here:
Use Cases: Concept Exploration
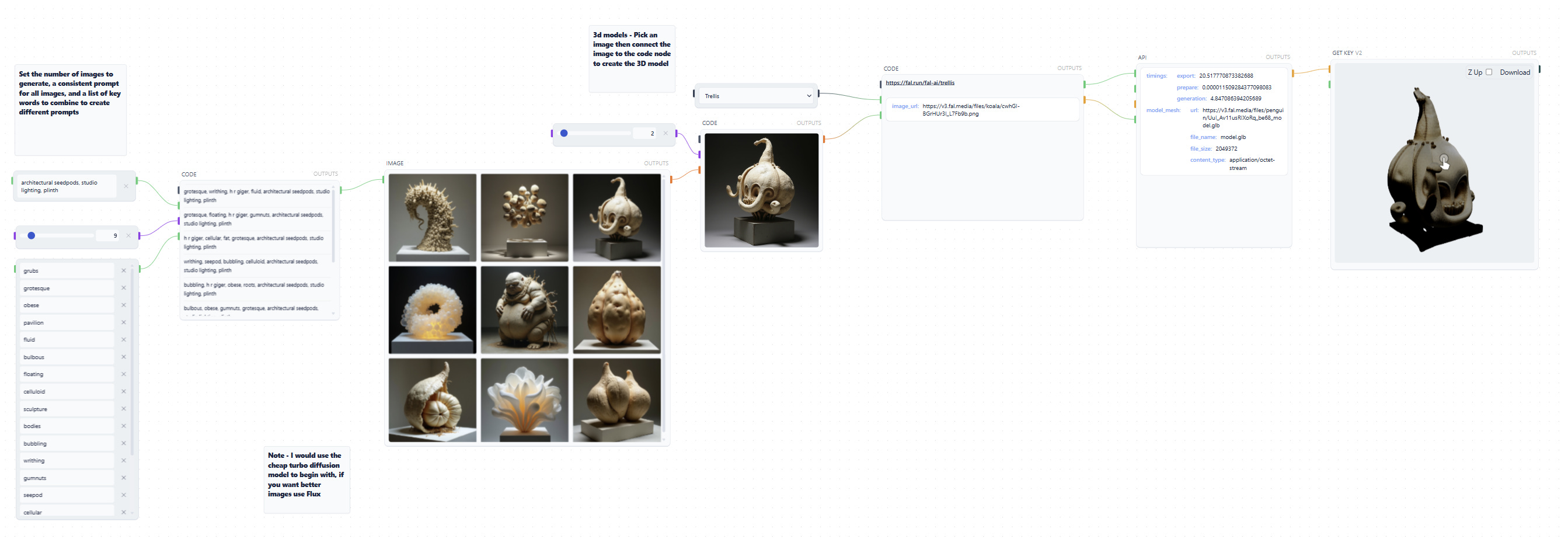
We could also use Runchat to generate multiple images based off some concepts we provide, then build a UI for selecting from these images and subsequently generating mesh models. The image preview component supports viewing grids of images, so we can review our options either in Runchat in the browser or natively within Grasshopper.
If you want try out the text to 3d workflow in Grasshopper you can grab the grasshopper definition here: